
pythonをやっていて便利だと思うことにスクレイピングがあります。そのスクレイピングでも必ずと言っていいほど出てくるライブラリそれはrequestsです。
今回はrequestsライブラリで特定のURLに接続して情報を取得するプログラムをつくってみました。
requestsライブラリは、URLを指定するだけで簡単にURLの情報が取得できるスクレイピングには必須のライブラリです。
requestsライブラリのインストール(Windows)
Pythonの標準ライブラリではないので以下のコマンドでインストールする必要があります。
※Anacondaなどで構築されている場合は最初から入っています。
pip install requests- 以下の画面が表示されればインストール完了
requestsライブラリを利用したプログラムサンプル
上記でrequestsライブラリはインストールできたのでサンプルプログラムを作成
#自分のレンタルサーバーのwelcomeページの文字列データを取得
#requestライブラリを使用する
import requests
#取得したURLを記述
url= "http://kajiblo.hippy.jp/welcome.html"
#URLの情報を取得
response = requests.get(url)
#日本語の文字化け防止
response.encoding = response.apparent_encoding
#アクセスしたURLのエンコーディング方式を返す
print(response.apparent_encoding)
#ステータスコード(200ならOK)
print(response.status_code)
#アクセスしたurlを返す
print(response.url)
#取得した文字列データを表示する。
print(response.text)
取得したURLの内容に日本語が含まれていて、文字化けが発生した場合は、response.apparent_encodingを使えば、大体文字化けが解消されます。
正しく表示できる文字コードを自動的に選んでくれる。
VS Codeで実行した結果
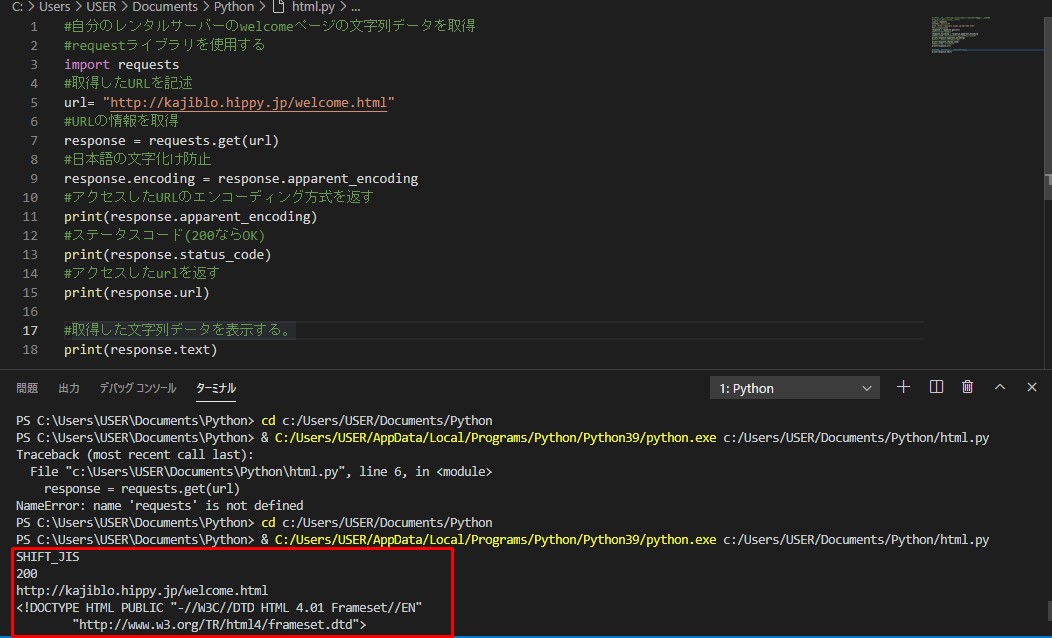
requests.getで取得できる情報
requests.getで主に取得できる情報は以下の通りです。
| メソッド | 説明 |
|---|---|
| .text | 文字列データ |
| .content | バイナリーデータ |
| .url | アクセスしたURL |
| apparent_encoding | 推測されるエンコーディング方式 |
| .status_code | HTTPステータスコード(200:OK、404:見つからなかった etc) |
| .headers | レスポンスヘッダー |
まとめ
- ライブラリのインストールは、pipコマンドでインストールする。
- response.apparent_encodingは、とりあえず書いておく
- requests.getは簡単にWEBページの情報を取得できる


コメント