
勉強がてらpythonで日本郵便から提供されている郵便番号をダウンロードして、データベース(sqlite3)に登録までを行うPGを作成してみました。細かいエラー処理等は書いていませんが、pythonはwebのファイルダウンロードからデータベースの登録までの一連の作業が簡単にできるので便利だと思いました。
概要
簡単な処理の流れ
簡単な処理の流れは以下の通りです。エラー処理等は書いてません。まだまだ改良の余地はあると思います。
- 日本郵便からrequests.getでzipファイルをダウンロード
- ダウンロードしたzipファイルを解凍(csvファイルになる)
- 解凍したcsvファイルを読み込む
- 読み込んだデータをsqlite3のデータベースに登録する。
サンプルプログラム
import requests
import zipfile
import pandas
import sqlite3
#郵便局のサイトから取得するファイルを指定
url = 'http://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip'
#データベース指定
dbname = "testdb"
#URLを指定してファイルをダウンロードする
#Split('区切り文字')[最大分割回数]-1は最後の要素
#独自関数(URLに指定されたファイルをダウンロード)
def dl_file(url):
#ファイル名を取得
filename = url.split('/')[-1]
#staem=Trueは、イテレータ形式で取得するためrequestの応答が終わる前に読み取りできる
#大きなデータの場合に付与する
rq = requests.get(url, stream=True)
#バイナリモードで開く
with open(filename, 'wb') as f:
#1024バイト単位で書き込み
for chunk in rq.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
return filename
# ファイルが開けなかった場合は False を返す
return False
#独自関数(ZIPファイルを解凍する)
def zip_extract(filename):
target_directory = '.'
zfile = zipfile.ZipFile(filename)
zfile.extractall(target_directory)
#本処理
# 郵便局のWEBサイトから郵便番号データをダウンロード
filename = dl_file(url)
#ファイル名が返ってきたら成功
if filename:
print('{} のダウンロードが完了しました。'.format(filename))
#カレントディレクトリのZIPファイルを解凍する。
zip_extract(filename)
#pandasで郵便番号データ(CSV)を読み込む
df = pandas.read_csv(filename,encoding="shift-jis",names=
["oldzipcode","zipcode","kana_ken","kana_sikucho","kana_choiki"
,"kan_ken","kan_sikucho","kan_choiki","hukusuchoiki","koji","chome"
,"hukusu_zipcode","update","reason"])
#DB接続&作成
conn = sqlite3.connect(dbname)
c = conn.cursor()
df.to_sql("jpcode", conn, if_exists="replace")
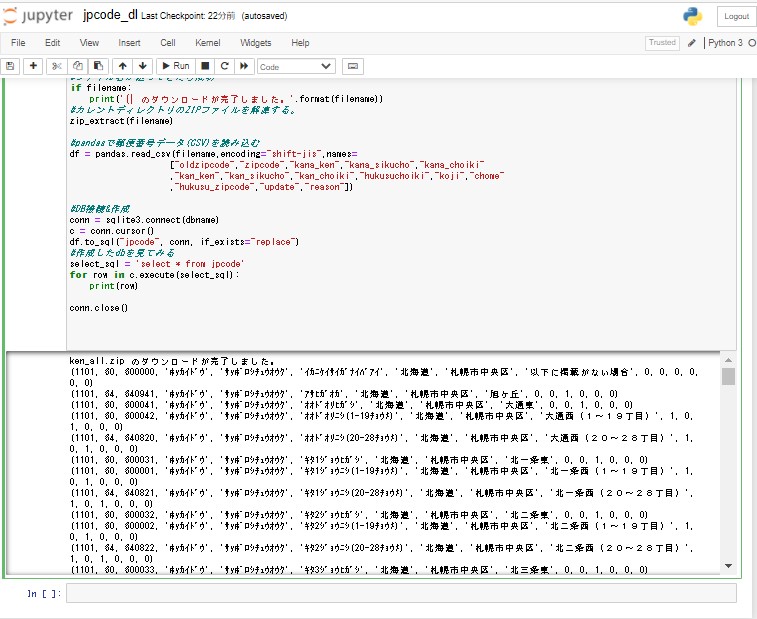
#作成したdbを見てみる
select_sql = 'select * from jpcode'
for row in c.execute(select_sql):
print(row)
conn.close()jupyter Notebookで実行した結果
郵便番号データファイルについて
取得ファイル
郵便番号データは、全国の読み仮名データの促音・拗音を小書きで表記するもの(zip形式)を以下のサイトから直接ダウンロードしています。

http://www.post.japanpost.jp/zipcode/dl/kogaki/zip/ken_all.zip
www.post.japanpost.jp
レイアウト
郵便番号データのレイアウトは以下の順番となっているようです。
- 全国地方公共団体コード・・・半角数字
- (旧)郵便番号(5桁)・・・半角数字
- 郵便番号(7桁)・・・半角数字
- 都道府県名・・・半角カナ
- 市区町村名・・・半角カナ
- 町域名・・・半角カナ
- 都道府県名・・・漢字
- 市区町村名・・・漢字
- 町域名・・・漢字
- 一町域が二以上の郵便番号で表される場合の表示(「1」は該当、「0」は該当せず)
- 小字毎に番地が起番されている町域の表示(「1」は該当、「0」は該当せず)
- 丁目を有する町域の場合の表示「1」は該当、「0」は該当せず)
- 一つの郵便番号で二以上の町域を表す場合の表示(「1」は該当、「0」は該当せず)
- 更新の表示(「0」は変更なし、「1」は変更あり、「2」廃止(廃止データのみ使用))
- 変更理由(「0」は変更なし、「1」市政・区政・町政・分区・政令指定都市施行、「2」住居表示の実施、「3」区画整理、「4」郵便区調整等、「5」訂正、「6」廃止(廃止データのみ使用))
サンプルプログラムのメモ
- import requestsは,日本郵便のサイトからファイルをダウンロードする際に使用
- import zipfileは,ダウンロードしてきたファイルを解凍する際に使用
- import pandasは,csvファイルを読み込む際に使用(データフレームとして取得)
- import sqlite3は,データベース登録用。pythonでは標準ライブラリなのでこれだけで使えるようになる。
- 独自で関数を作成する際は、defで定義する。
def 関数名(引数1, 引数2, ..., 引数n):
![]()

コメント