
最近、pythonでFastAPIというWEBフレームワークを勉強しています。FastAPIでデータベースを使うとなったときにマッピングに使われているのが、SQLAlchemyです。
前から名前を聞いたことはあって、pythonとデータベースをマッピングするORMというのは知っていました。ただ、普段システム保守でSQLをよく書くことがあったのでpyodbcというodbc経由でデータベースに接続して直接SQLを書けばよいと思っていました。
今回FastAPIを勉強するにあたってそうもいかなくなったのでSQLAlchemyを使ってみることにしました。当記事はSQLAlchemyとpyodbcを使用してSQLServerに接続してデータベースとテーブルを実際に作成したときの対応方法について書こうと思います。
SQLAlchemyとは?
SQLAlchemyは、Pythonで一番利用されているORM(ORマッパー)のライブラリです。
ORMは、(Object Reration Mapper)の略でpythonのプログラムで記述したclassとテーブルを1対1でマッピングして、class経由でCRUD操作を行えます。
有名どころで言うと以下のデータベースに対応しています。
・MySQL
・Oracle
・PostgreSQL
・SQLite3
SQLAlchemyを使うメリット
SQLAlchemyを使用するメリットをざっくり上げると
データベースの違いを吸収してくれる
一つのデータベースだけしか使ったことがない場合は、経験がないかもしれませんがデータベースによってSQL文の書き方が違うことがあります。例えば、SQLで上位10件を抽出する場合は、
SQL SERVERの場合は、以下のようになります。
SELECT TOP 10 * FROM テーブル名
次にMySQLやOracleの場合は
SELECT * FROM テーブル名 LIMIT 10;
となります。仮にプログラムにSQLを直接書いていた場合、DBを変更するとPGの修正も必要ですが、SQLAlchemyの場合は、PGの修正は、接続部分の設定のみでSQL文を修正する必要はありません。
SQLを書く必要がない
SQLを書くのが苦手な人でもSQLを記述せずにデータベースのCRUD操作ができます。
pythonのWEBフレームワークでは、ORMの利用がデフォルト
最近のpythonのWEBフレームワークでは、データベースに接続する際は、ORMを使用した接続が主流です。Djangoは専用のORMですがFlaskやFastAPIは、SQLAlchemyを使用するのが主流となっています。
SQLAlchemyをテーブルを作成する(SQL Severの場合)
事前にSQL Serverに空のデータベースを作成してください。当記事ではtestというデータベースを事前に作成しています。
sqlalchemyのインストール
PythonでSQLAlchemyを使うにはPythonの環境にSQLAlchemyのライブラリをインストールする必要があります。python環境に以下のコマンドでインストールしてください。
#pip環境の場合:
pip install sqlalchemy
#anaconda環境の場合:
conda install sqlalchemy
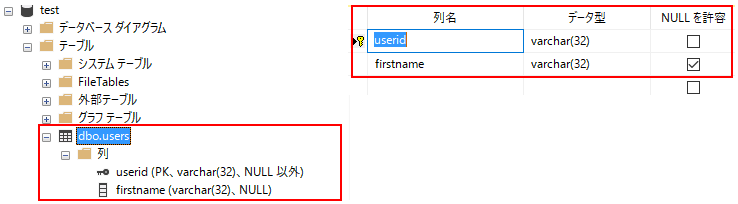
今回作成するテーブル
今回は、sqlalchemyでtestというDBにusersというテーブルを作成しようと思います。
DB名:test
作成するテーブル:users
| 列名 | 主キー | タイプ |
|---|---|---|
| userid | 〇 | 文字列 |
| firstname | 文字列 |
全ソース
任意のファイル名.pyファイルを新規作成し、以下のように記述します。
※ここではdb.pyというファイルを作成しています。
import urllib
from sqlalchemy import Column,String, create_engine
from sqlalchemy.ext.declarative import declarative_base
#pyodbcの接続文字列
#ドライバー名
driver = r'ODBC Driver 17 for SQL Server'
#インスタンス名(サーバ名\インスタンス名)
server = r'localhost\xxxx'
#SQL Serverに接続するユーザー名
username = 'ユーザー名'
#パスワード
password = 'パスワード'
#データベース名
db = 'test'
#ODBCの文字列を作成
odbc_connect = urllib.parse.quote_plus(
'DRIVER={%s};SERVER=%s;UID=%s;PWD=%s;DATABASE=%s' % (driver, server, username, password,db))
#データベースに接続するエンジンを作成
engine = create_engine("mssql+pyodbc:///?odbc_connect=%s" % odbc_connect,echo=True)
#テーブル定義の基底クラス
Base = declarative_base()
#基底クラスBaseを継承してクラスを作成
class User(Base):
__tablename__ = 'users'
userid = Column('userid',String(32),primary_key = True)
username = Column('firstname',String(32))
Base.metadata.create_all(bind=engine)処理解説
odbcの設定
#odbcの接続文字列
#ドライバー名
driver = r'ODBC Driver 17 for SQL Server'
#インスタンス名(サーバ名\インスタンス名)
server = r'hostname\instance'
#SQL Serverに接続するユーザー名
username = 'ユーザー名'
#パスワード
password = 'パスワード'
#データベース名
db = 'test'
sqlalchemyでSQLServerに接続する際は,pyodbc経由またはPymssqlで接続する必要があります。調べたところPymssqlは動作が不安定とのことで今回はpyodbc経由にしています。
ODBドライバ名は、ODBCデータソースアドミニストレーターの名前と同じにします。
私の場合はODBC Driver 17 for SQL Server
インスタンス名は、サーバー名\インスタンス名を入力します。バックスラッシュをエスケープ文字ではなく単なる文字列として扱うため先頭にrを付与しています。
ユーザー名とパスワードはSQL Serverに接続する際のユーザー名とパスワードを入力します。
(混合モード)
データベース名は、事前にSQL Serverで作成したデータベース名を記載します。
接続文字列の作成
#ODBCの文字列を作成
odbc_connect = urllib.parse.quote_plus(
'DRIVER={%s};SERVER=%s;UID=%s;PWD=%s;DATABASE=%s' % (driver, server, username, password,db))上で変数にセットしたodbcの設定から接続文字列を作成します。urllib.parse.quote_plus()でエンコードしています。
エンジンの作成
#データベースに接続するエンジンを作成
engine = create_engine("mssql+pyodbc:///?odbc_connect=%s" % odbc_connect,echo=True)create_engine の引数にodbcの接続文字列を入れて接続するためのエンジンを作成します。
ちなみにecho=True は、SQL発行時に実行内容を標準出力する設定です。指定なしの場合は実行しても何も出力されないので最初は出力したほうが良いと思います。
基底クラスBaseを宣言
#テーブル定義の基底クラス
Base = declarative_base()モデルとなる基底クラスを作成しています。これでBaseにモデルのベースとなるクラスが作成されます。後ほど作成するusersクラスは、この基底クラスのBaseを継承して作成します。
テーブルにマッピングするクラスを作成
#基底クラスBaseを継承してクラスを作成
class User(Base):
__tablename__ = 'users'
userid = Column('userid',String(32),primary_key = True)
username = Column('firstname',String(32))__tablename__ = 'users'は、作成したテーブル名を指定しています。その下は、カラムを作成しています。
テーブルの作成
Base.metadata.create_all(bind=engine)Baseクラス内のデータベースのテーブル情報を管理しているmetadataを新規で作成することでテーブルが作成されます。(bind=engine)は、使用するエンジンを指定しています。
プログラムの実行
上記で作成したdb.pyファイルをファイルが存在しているディレクトリに移動して実行します。
cd <db.pyが存在するフォルダ>
python db.pyこれでSQL Serverを確認すると以下のようにテーブルが作成されていると思います。

コメント