
いきなりですが、以下のようなある程度整理されたExcelファイルを集計することってありませんか?
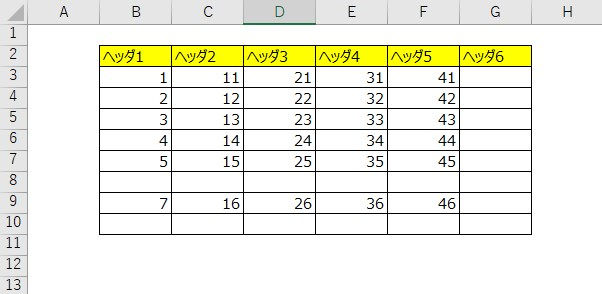
こんな時、pythonのpandasライブラリのread_excelを使えば簡単にdataframe形式で取得することが可能です。dataframe形式にさえしてしまえば、pythonは、強力なデータ分析のライブラリで集計したり、グラフに出力することができます。
ということで今回は、pandasを使ってExcelデータを読み込む方法について紹介したいと思います。
尚、dataframeというpythonが扱える表形式のデータはJupyterで実行するとそのまま表形式で結果が表示されるのでVSCode + Jupyterの環境で実行することをお勧めします。
Excelデータを読み込む
pythonでExcelデータを読み込む方法はいろいろありますが、上記のようなExcelだとpandasライブラリのread_excelで取得するのが一番簡単です。
※ExcelファイルがC:\test配下に格納されている前提
基本構文 pandas.read_excel(Excelファイルのフルパス)
import pandas as pd
excelfile = r'C:\test\test.xlsx'
df = pd.read_excel(excelfile)
df※importする必要はありませんが、Excel読込時にopenpyxlを使っているのでopenpyxlのインストールが必要です。
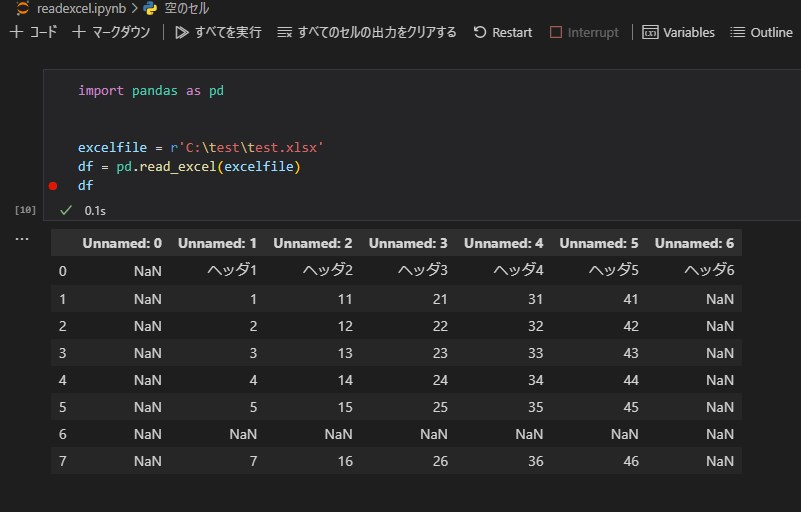
めちゃめちゃ簡単に取れましたね!!
基本はこれだけでExcelデータを取得できます。
ただ、今回は気になるところがあります。
- データが2行目から始まっている。
- ヘッダーもデータとして認識している。
- 何も入っていない行(欠損値)も取得している。
- 何も入っていない列(欠損値)も取得している。
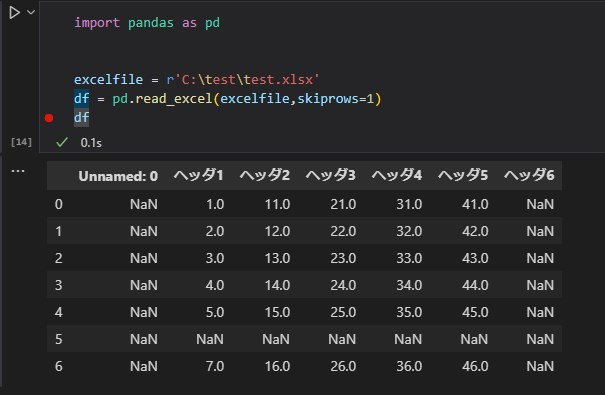
skiprowsで指定行をスキップする
import pandas as pd
excelfile = r'C:\test\test.xlsx'
df = pd.read_excel(excelfile,skiprows=1)
dfskiprows=intを指定すると指定された行をスキップして読み込みます。
ヘッダをつけたい
以下のようにheader=intで指定した行をヘッダーにすることが可能です。
import pandas as pd
excelfile = r'C:\test\test.xlsx'
df = pd.read_excel(excelfile,skiprows=1,header=0)
df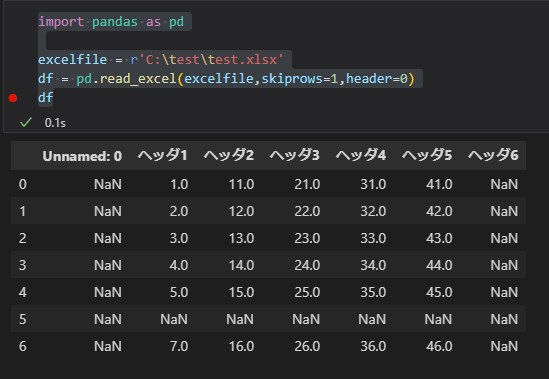
不要な行や列を削除する
不要な行の削除
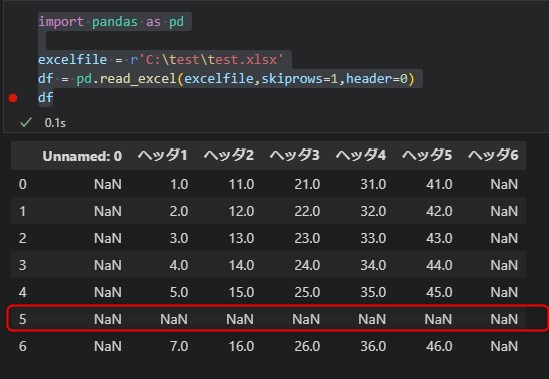
上記データでは赤枠の行は値が何も入っていないので不要です。この場合は
dropna(how=’all’)ですべての値が欠損値(NaN)の行を削除してくれます。
import pandas as pd
excelfile = r'C:\test\test.xlsx'
df = pd.read_excel(excelfile,skiprows=1,header=0)
df = df.dropna(how='all')
df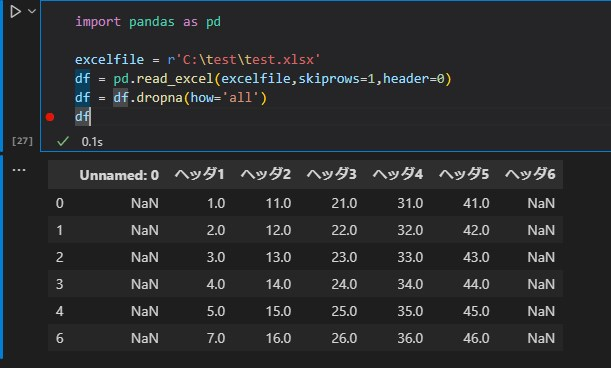
※dropna(how=’any‘)にすると欠損値が一つでも含まれる行があれば削除されます。
不要な列を削除
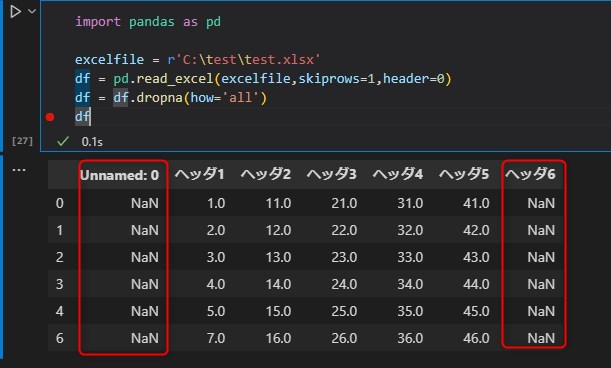
不要な列を削除したい場合は、以下のように引数axis = 1またはcolumnsを付与します。
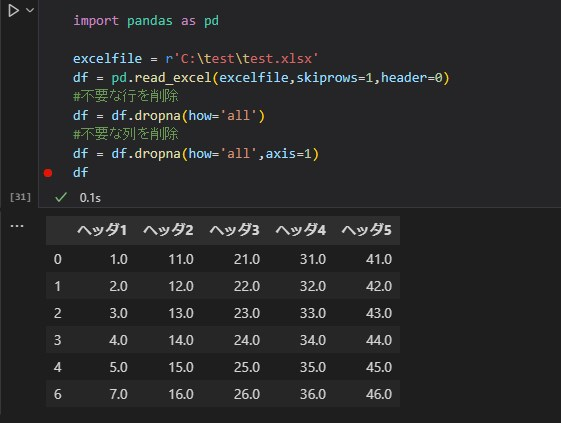
これで今回の表形式のデータはきれいに読み込むことができました。これでPython側で集計することが可能になります。今回のExcelデータはどちらかというとまだ整理されていたほうなのです。他にも様々なパターンがあるので都度更新出来たらと思います。
まとめ
- read_excel(excelfile,skiprows=int)で指定の行の読込をスキップできる。
- read_excel(excelfile,header=int)で指定の行をヘッダー行にする。
- dropna(how=’all’)ですべての値が欠損値(NaN)の行を削除
- dropna(how=’all’,axis=1)ですべての値が欠損値(NaN)の列を削除
- dropna(how=’any’)はひとつでも欠損値の行や列があった場合に削除


コメント