
最近、IT業界ではDX(デジタルトランスフォーメーション)という用語がよく出てきます。
これは、今使用しているシステムが限られた部門ごとに構築されて、会社全体としてデータがうまく活用できない課題を解決するための考え方です。
現在構築されているシステムが、複雑なカスタイズをされたことによる、ブラックボックス化などが原因と言われています。
これらの問題が解決できない場合は、2025年以降、年間最大12兆円の経済損失が生じる可能性があると経済産業省が警告しています。これが最近よく聞く「2025年の崖」という問題です。
Data Factoryは、そんな2025年の崖問題を解決するために使われるETLツールです。
私がこの記事を書く前に知っていた知識は、上に書いたことぐらいです。
そこで、いきなりAzure Data Factoryの環境が用意されたので一から勉強してみたいと思います。
その勉強段階で調べたことを備忘録として残しておこうと思います。
Azure Data Factoryとは?
会社内のいろいろな部署で使用されているシステムに蓄積されているデーターを一元管理できるように、データの抽出・加工・格納の処理を自動化するためにマクロソフトが提供しているAZureのサービスです。このようなサービスは一般的にETLツールと呼ばれています。
このETLは何の略?かというとデータの
- E:Extract(抽出)
- T:Transform(加工)
- L:Load(格納)
この頭文字をとってETLツールと言われています。
Azure Data Factoryの基本用語
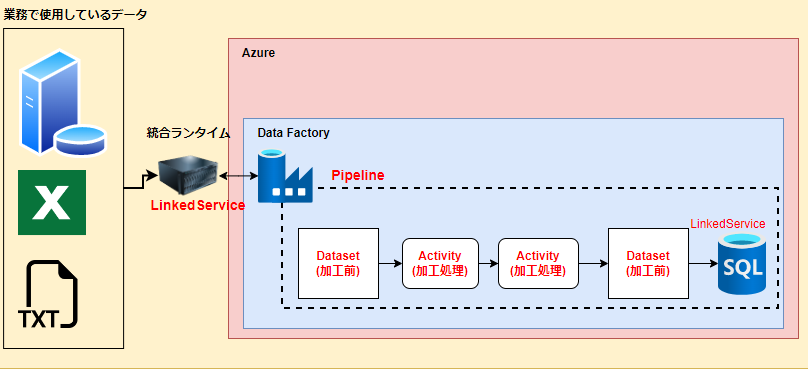
Azure Data Factoryを使うときの基本構成は、いろいろありますが、今回は以下のパターンで考えてみたいと思います。
Linked Service
LinkedServiceは、Azure Data Factoryとデータストアを接続する定義のことです。
データストアに接続するために必要なデータベース名やユーザーID/パスワードなどを定義する接続文字列みたいなものです。
図でいうと、業務で使用しているデータが格納されているデータストアとData Factoryを繋ぐ定義と、AzureのSQL DatabaseとData Factoryをつなぐパターンで定義するようになります。
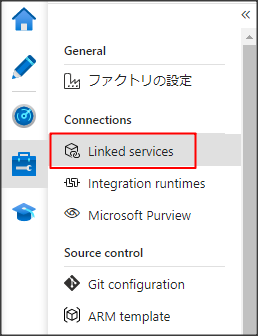
このLinked serviceはAzure DataFactoryの画面でManage→Linked serviceで定義を作成します。
後述するDatasetなどもどこに接続するかの情報が必要なので、恐らく、一番最初に作成する定義だと思います。
統合ランタイム
統合ランタイムは、Integration Runtime(IR)とも呼ばれていて、AzureのDataFactoryとデータストアを接続するときに橋渡し役としての役割を担っているサービスです。このIRは主に以下のパターンがあります。
Self-Hosted Integration Runtime (SHIR)
Azure以外の別のネットワークに存在するデータストアとのやりとりが発生する場合は、SHIRを構築します。構築するSHIRとなるサーバーなどにサービスをインストールする必要があります。
AutoResolveIntegrationRuntime
同じAzure内にと接続するときに使用するRuntimeです。AutoResolveIntegrationRuntimeは、その言葉通り、DataFactoryを作成したときに自動で作成されるデフォルトで作成されるIRです。
図でいうと、Azure内で使用しているSQL Databaseへの接続は、AutoResolveIntegrationRuntimeを使います。
Pipeline
パイプラインは、後述するActivityを論理的にグループ化されたものです。複数のActivityを一つにまとめたもので図で言うと加工前のデータをdatasetにセットして加工処理後にSQL Databaseにデータを流し込む一連の作業を一つにまとめたものです。
JP1でジョブ管理したことがある人は、ジョブネット的な感じです。
このPipelineをトリガーなどで毎日決められた時間に実行するなどの処理を行うことができます。
Data Factoryを使う上では、このPipelineをどうやって作成していくかがメインの作業だと思います。
Activity
上述のPipelineの中で行われている一つ一つの処理のことです。JP1でいうとジョブそのものにあたります。
Dataset
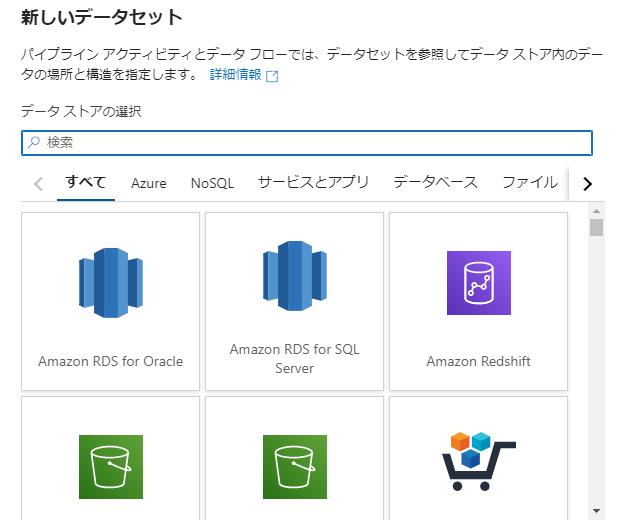
取得してきたデータや加工したデータを一時的に格納するデータ構造のことです。データを一時的に格納する変数の箱みたいなイメージです。この箱に、格納するテーブルのデータやファイルのデータを指定することができます。このDatasetにセットできる構造は以下のようにいろいろなサービスから選択することができます。
まとめ
DataFactoryを始める際の手順は基本的に以下のような流れになると思います。
- 統合ランタイム環境を構築する(Azure以外からデータを取得したい場合)
- データを取得したいデータストアーのLinkedServiceを定義する。
- Datasetを定義する
- Pipeline(Activity含む)を作成する

コメント