💡背景と目的
システム改修やデータ連携の場面で、CSVファイルの仕様が変更されることはよくあります。 たとえば「1項目(列)を追加したけど、それ以外のデータは変わっていないはず」というケース。
でも、本当に他の項目に差異がないかを確認するには、目視では限界があります。 そんなときに役立つのが、Pythonとpandasを使った差分チェックスクリプトです!
🧪用途:こんなときに使える!
- 項目追加後のリグレッションチェック
- データ移行後の整合性検証
- 差分が追加列だけかを確認したいとき
- 1GB超の大容量CSVを扱う必要があるとき
🧰 使用ツール
- Python 3.x
- pandas(1.1以降推奨)
🧾 スクリプト全文
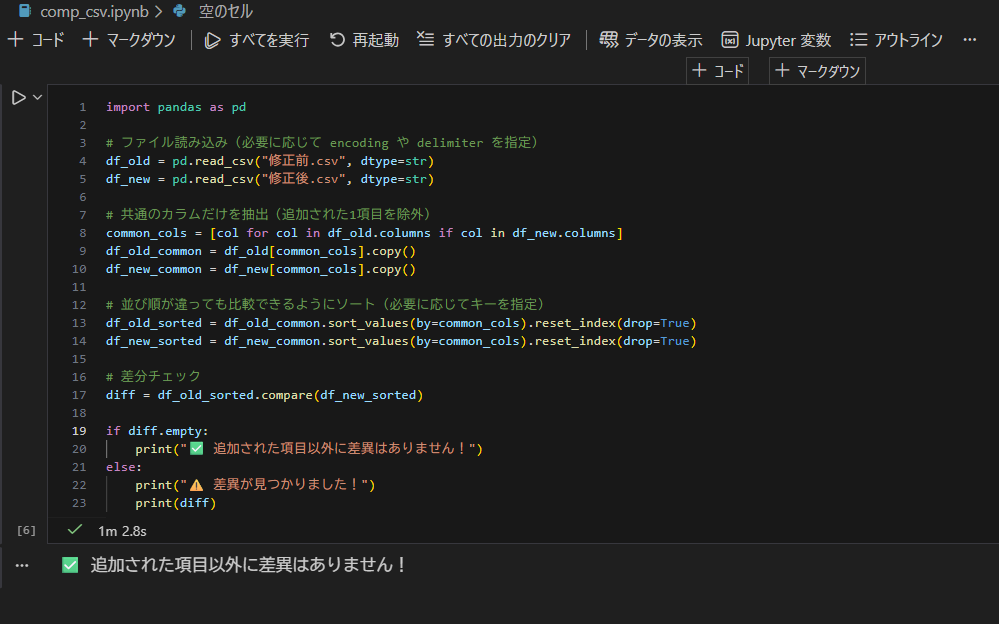
import pandas as pd
# ファイル読み込み(文字列として統一)
df_old = pd.read_csv("old.csv", dtype=str)
df_new = pd.read_csv("new.csv", dtype=str)
# 共通カラムのみ抽出(追加列を除外)
common_cols = [col for col in df_old.columns if col in df_new.columns]
df_old_common = df_old[common_cols].copy()
df_new_common = df_new[common_cols].copy()
# 並び順を揃える(比較キーがあれば指定)
df_old_sorted = df_old_common.sort_values(by=common_cols).reset_index(drop=True)
df_new_sorted = df_new_common.sort_values(by=common_cols).reset_index(drop=True)
# 差分チェック
diff = df_old_sorted.compare(df_new_sorted)
if diff.empty:
print("✅ 追加された項目以外に差異はありません!")
else:
print("⚠️ 差異が見つかりました!")
print(diff)
追加した列は当然差異が出るので除外しています。私はVscodeのJupyterで実行しました。
🔍 解説ポイント
| 処理内容 | 説明 |
|---|---|
dtype=str | 型の違いによる誤検出を防ぐため、すべて文字列として読み込む |
common_cols | 旧ファイルと新ファイルの共通カラムを抽出(追加列を除外) |
sort_values | 行の順番が違っても正しく比較できるようにソート |
compare() | pandasの差分検出メソッド。差異があるセルだけを抽出 |
🛠️ 応用ポイント
- 比較キーがある場合は
sort_values(by=["ID"])のように指定するとより正確! - 差分をCSV出力したい場合は
diff.to_csv("diff.csv")を追加すればOK! - 差分が多い場合は
head()で一部だけ表示するのもおすすめ!
🧭 まとめ
このスクリプトを使えば、仕様変更後のCSVファイルが正しく生成されているかを高速・確実にチェックできます。 特に大容量ファイルや監査対応が必要な現場では、こうした自動チェックがとても有効です!


コメント